

Users swiftly select LLM-generated suggestions via gaze on an AR headset with a ring for real-time note-taking in GazeNoter.
(a) An AR headset and a ring are worn for note-taking in a speech/discussion.
(b) As the speech progresses, the system extracts context keywords from the most recent sentence spoken.
(c) Users can select either these context keywords or customized keywords. The system then automatically generates candidate sentences based on these selections.
(d) Users could explore and select derivative keywords beyond the context of the speech, helping users generate candidate sentences that best align with their note-taking intentions.
(e) Users could review the notes recorded through three different processes:
(Blue) Normally, a sentence is recorded as a note.
(Green) If no candidate sentences align with users’ intentions, users could record all selected keywords as a note.
(Red) If users need to take a note hastily, they could select context/customized keywords, skipping step (d), to record these keywords as a quick note
GazeNoter
GazeNoter was my graduation thesis during my master’s degree in CS, a futurist user-in-the-loop AR system designed to revolutionize how we take notes in static and dynamic scenarios.
1. Introduction
In a world increasingly reliant on real-time data and swift interaction as companies like Apple push the envelope with innovations such as the Vision Pro XR headset, the landscape of how we interact with digital information is rapidly evolving.
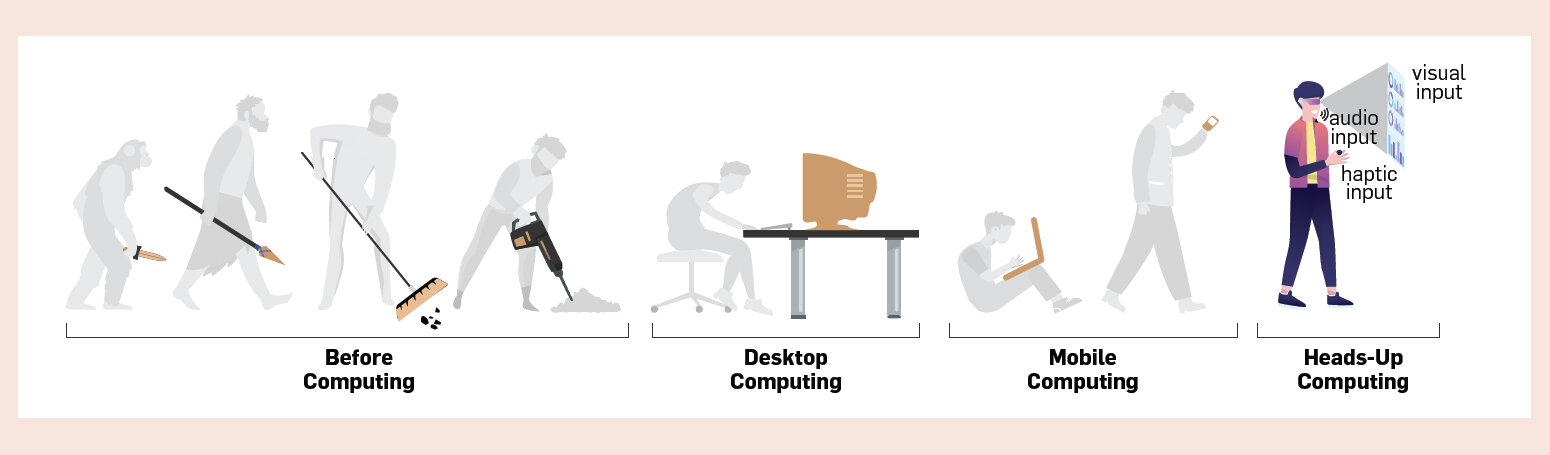
Human’s co-evolution with tools: entering the era of heads-up computing.
Shengdong Zhao, Felicia Tan, and Katherine Fennedy. 2023. Heads-Up Computing Moving Beyond the Device-Centered Paradigm.
Commun. ACM 66, 9 (Aug. 2023), 56–63.
Our project GazeNoter introduces a revolutionary system blending Augmented Reality (AR) and Artificial Intelligence (AI) to transform how we take notes during speeches and meetings.
Traditional methods of jotting down pen or digital notes can be cumbersome and often distract from the actual conversation or presentation.
GazeNoter, however, simplifies this process via a user-in-the-loop AI system that allows users to select LLM-generated suggestions through gaze interactions on an AR headset.
2. Feature and flow
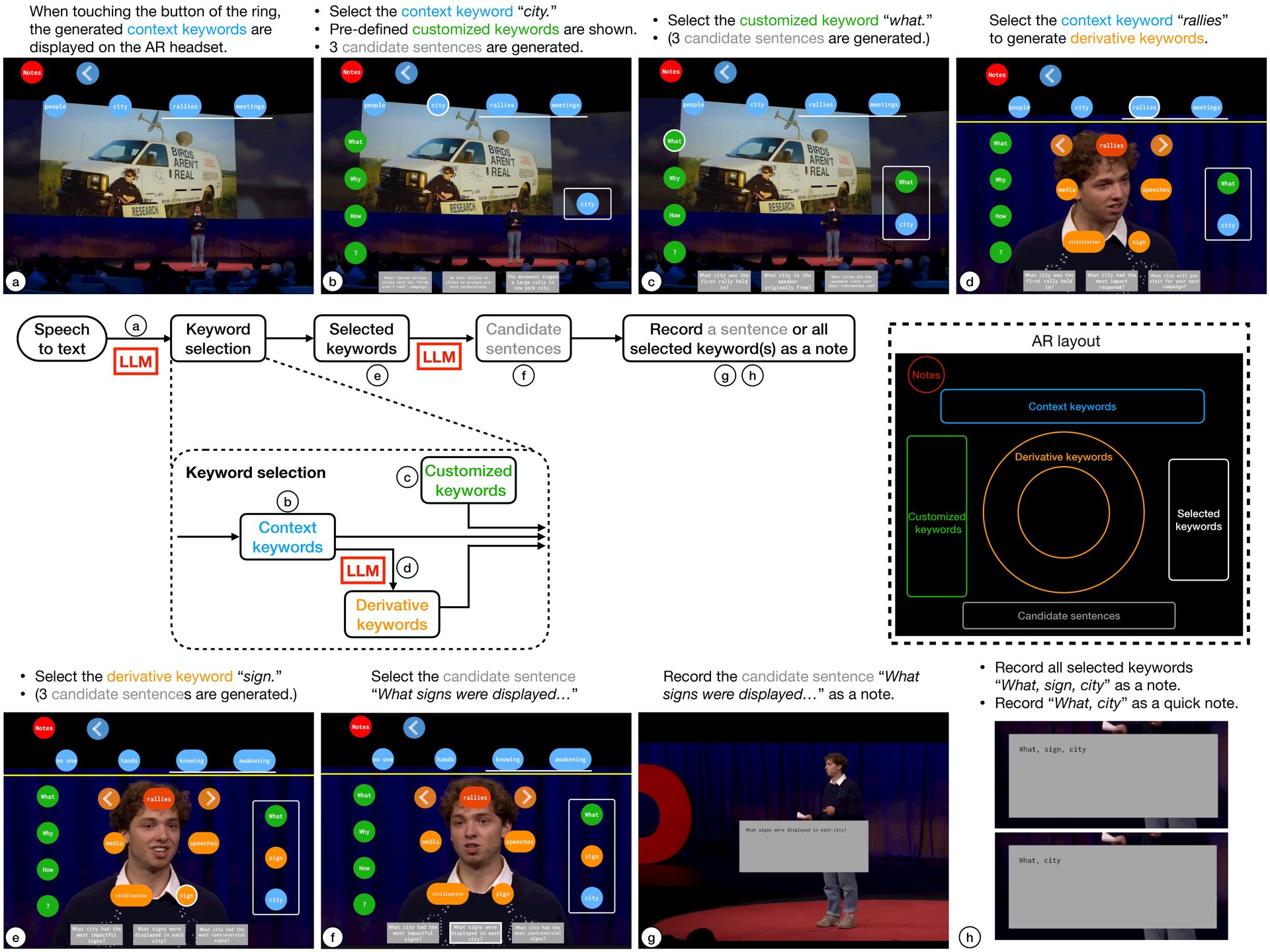
GazeNoter flowchart and usage demonstration.
(Middle) The flowchart of GazeNoter.
(Right) The AR layout, is displayed only when the ring is touched.
(a) GazeNoter extracts context keywords from the latest sentence of the speech.
(b) Once the user selects a context keyword, “city”, the pre-defined customized keywords are shown, and 3 candidate sentences are generated based on the context keyword.
(c) The user selects a customized keyword, “what”, and the candidate sentences are updated accordingly.
(d) If the user wants to take a beyond-context note and no desired keyword is among the context keywords, the user selects the most relevant context keyword, “rallies”, to generate derivative keywords.
(e) The user selects a derivative keyword, “sign”, and the candidate sentences beyond the context are updated accordingly.
(f) The user selects the candidate sentence best matching the intention, “What signs were displayed…”, to record as a note.
(g) The recorded note is shown.
(h) If no candidate sentences match the intention in
step (f), the user could also record all selected keywords as a note (upper). If the user needs to take a note hastily, the user could select only context (or also customized) keywords to record these as a quick note (lower), only from steps (a)(b) or (a)(b)(c).
GazeNoter leverages the capabilities of Large Language Models (LLMs) with AR technology, enabling users to select suggestions through gaze interactions on an AR headset.
The core idea is to facilitate note-taking without requiring manual typing or voice inputs. This system particularly shines in contexts where maintaining attention or interacting socially is crucial, such as during speeches or interactive meetings.
In the innovative realm of GazeNoter, we explore three keyword types essential for enhancing note-taking efficiency and alignment with user intentions: Context keywords, Customized keywords, and Derivative keywords. Let’s delve into each:
1. Context keyword: These keywords are extracted directly from the audio content as it is transcribed into text by the system’s AI. By detecting and extracting critical words from spoken inputs every few seconds, context keywords capture the immediate topical elements of the speech, providing a real-time basis for notes.
2. Customized keyword: Users personalize these keywords based on their unique note-taking preferences and needs. This feature allows users to incorporate specific terms that they frequently use or that are of particular relevance to their domain of interest. By selecting a context keyword, users can bring up their pre-defined customized keywords, enhancing the note’s relevance and personal utility.
3. Derivative keyword: These are generated by prompting the AI to derive words that are contextually linked to but not directly mentioned within the user-selected context keyword. This allows for deeper exploration of related concepts or themes, extending the utility of the notes beyond the immediate context. For example, if “education” is a context keyword, derivative keywords might include related aspects like “learning methods” or “academic performance”.
Once users select any combination of Context, Customized, or Derivative keywords, the system automatically generates a set of three Candidate sentences. These sentences are dynamically crafted based on the selected keywords and displayed on the AR headset, allowing users to choose the sentence that best aligns with their intentions.
The complete note-taking process using GazeNoter.
The user selects three types of keywords and selects a candidate sentence to record as a note.
However, if users find that none of the generated Candidate sentences meet their needs, users can directly record all the selected keywords as a single note. This feature is particularly useful when the system-generated suggestions do not align well with the user’s objectives or when expedited note-taking is necessary.
Additionally, for quick note-taking without waiting for sentence generation or selecting from candidate sentences, users can immediately record just the context or customized keywords. This rapid recording acts as a ‘quick note,’ ensuring that critical keywords are captured instantly, thereby preserving the essence of the ongoing discussion or speech.
3. AR gaze selection
In response to the need for a more intuitive and unobtrusive confirmation mechanism in gaze selection technologies, particularly within AR environments, the design of a specialized ring provides an elegant solution.
The ring, equipped with a button, an infrared (IR) sensor, and spiral tracks, is worn on the index finger. Its primary function is to confirm selections made by the user’s gaze, pressing the button with the thumb executes the confirmation.
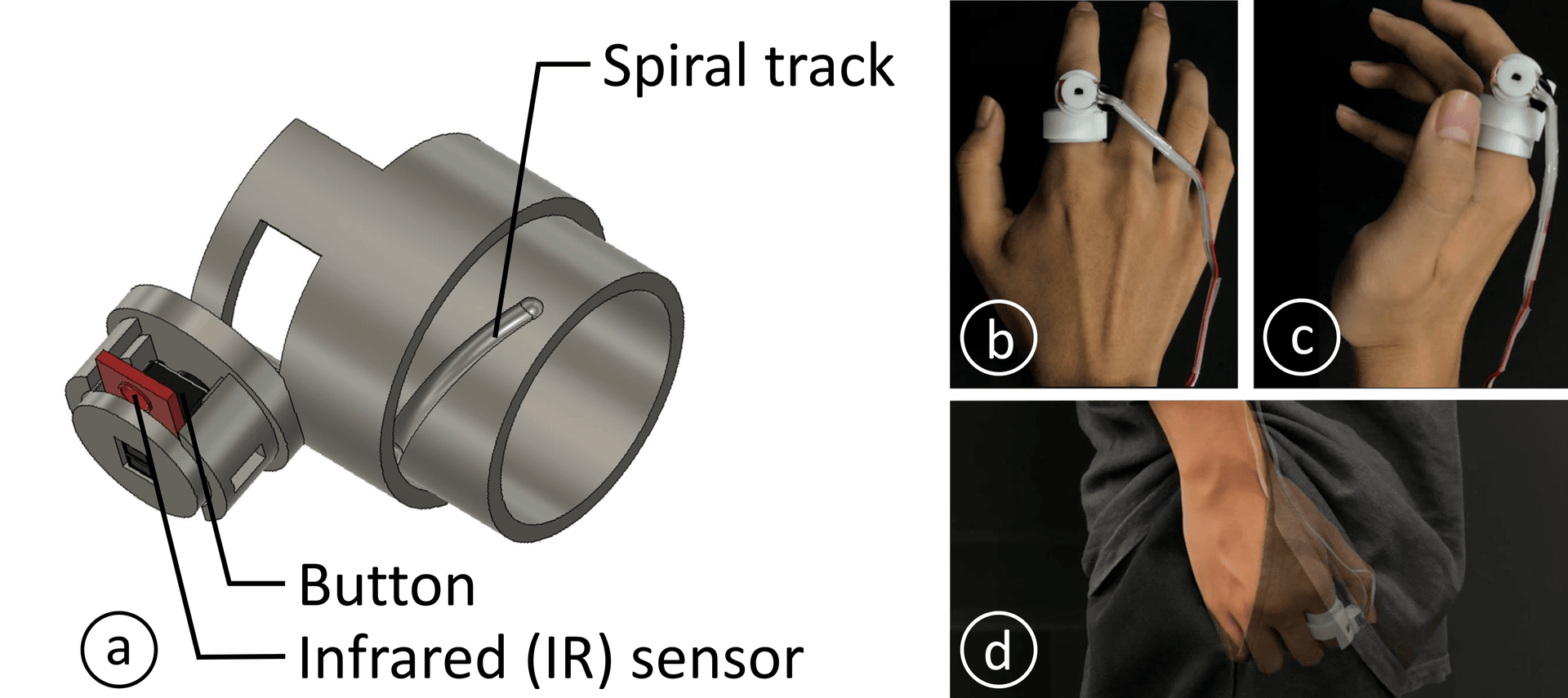

Design of the new gaze + ring mechanism for swift interaction.
(a) The hardware structure of the ring.
(b) The button can be withdrawn on the back of the finger, preventing interference with users.
(c) The button is extended for input.
(d) The ring can be used subtly, such as in a pocket.
(Right) Different input methods using the ring, including touch, click, double click, and withdrawing the ring when finishes note-taking.
This design elegantly circumvents the traditional reliance on more conspicuous and less subtle controllers or gesture-based inputs for AR interfaces, enhancing mobility and discretion.
• Button: A complementary design of the confirmation step that gaze tracking lacks. Clicking the button would select the object the user is gazing at.
• IR sensor: Only when the user’s thumb touches the button, AR content is displayed, facilitating seamless transitions between the virtual and real world.
• Spiral track: Extend and rotate the button 90° for better pressing.
4. User studies
We put GazeNoter to the test through two user studies: one in a static setting where users listened to speeches, and another in a mobile scenario involving walking meetings. The results were compelling. GazeNoter not only reduced the cognitive load and distraction compared to traditional note-taking methods but also improved the quality of notes and overall engagement with the task at hand.
GazeNoter usability demonstration in two scenarios.
(Left) Attending formal speeches in a static sitting condition.
(Right) Attending a walking meetings in a mobile walking condition.
5. Conclusion
In conclusion, we propose a real-time note-taking system, GazeNoter, by integrating a user-in-the-loop LLM system with gaze selection on an AR headset to generate notes that are both within-context and beyond-context, aligning the users’ intentions.
GazeNoter, through simple keyword and sentence selection processes on either smartphones or the AR headset, significantly outperforms both manual note-taking and automatic notes generated by the LLM in many metrics. Furthermore, when using the AR headset, GazeNoter demands less eye, head, and hand movement, leading to less distraction and cognitive load.
For more detailed insights into our research and findings, feel free to delve into our full paper!